
This is a prospective extension to Python dict .get() that solves a common problem in data applications. The bold proposal asks whether to include such an implementation in the core language or in a library, across languages used for data processing. See what you think..
Background & Why?
These days we have more data-oriented code being written (ML/AI,etc). Data is often “dirty” (missing values/spelling errors/grammar typos/etc). “Fuzzy” (less certain) matching can be useful in many of these cases (and traditionally in SQL we might use %LIKE%). Dictionary implementations (i.e. hashmap, hashtable, hashtree, associative-array, etc) are an efficient and simple lookup mechanisms. More specialised lookup data structures with other uses exist also, such as Bloom filters, Disjoint sets and Tries. They each respond as a boolean lookups – the input key is there, or the key is not; however it’s unconventional to think of their lookup with a confidence measure.
In data-oriented code, dictionaries are often used for matching data or conditionally joining datasets. When we cross (natural) languages we get more typo variations (in the general sense, double languages means double the varieties of typos) and therefore greater likelihood of mismatches when performing lookups (or translating) across those languages.
Implementations (EAGAR & LAZY)
Code Description:
Below is Python code using the difflib string similarity library. The code will perform a lookup in a dictionary (dict), using a double get_or_else mechanism. get_or_else has become a broadly adopted functional paradigm best practice in software engineering in order to replace if-else blocks with a (coupled) curried function. Coupling multiple get_or_else function calls is normal, yet tends to give more edge cases / complicates testing. It remains unconventional to throw confidence-based matching into this mix; which is precisely what we do here:
The dictionary lookup will either:
- match the
key, or - match the
key with a similarity score >= threshold=0.5, or - fail to match, and return
default_value.
Code Sample:

Code Breakdown
Obviously, the above looks like code golf, so let’s step through the call and show each operation:
(0) Standard Get or Else dict lookup:
The base operation is a standard dict key check using the get(..) method. get(..) ensures an exception is not raised if the key is not found. If the key is found it returns. (See the Runtime Analysis below for more on this execution, as it is evaluated after snippets 1-6).

(1) Similarity Scores:
Create a list of matches to each key. This is an O(n) operation, checking every dict key.

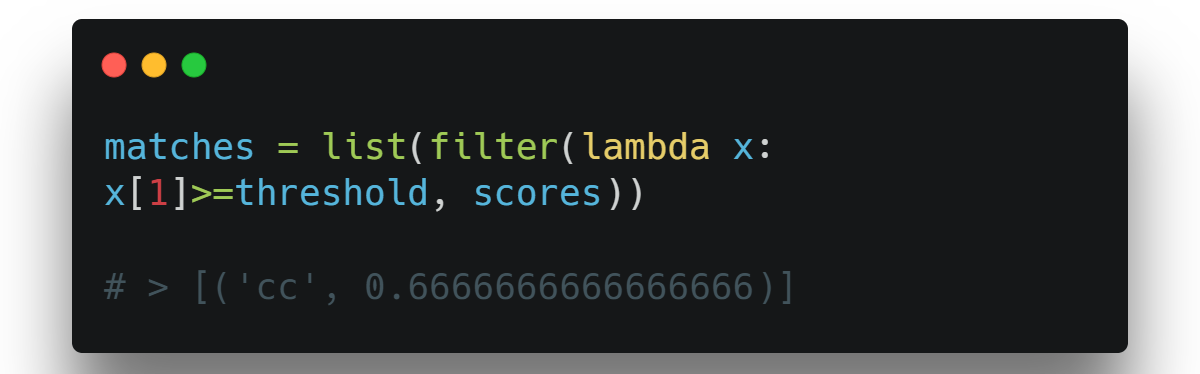
(2) Filter by Threshold Score:
Keep the keys with a similarity score that reaches or exceeds the threshold value. This is an O(n) operation, checking every dict key.
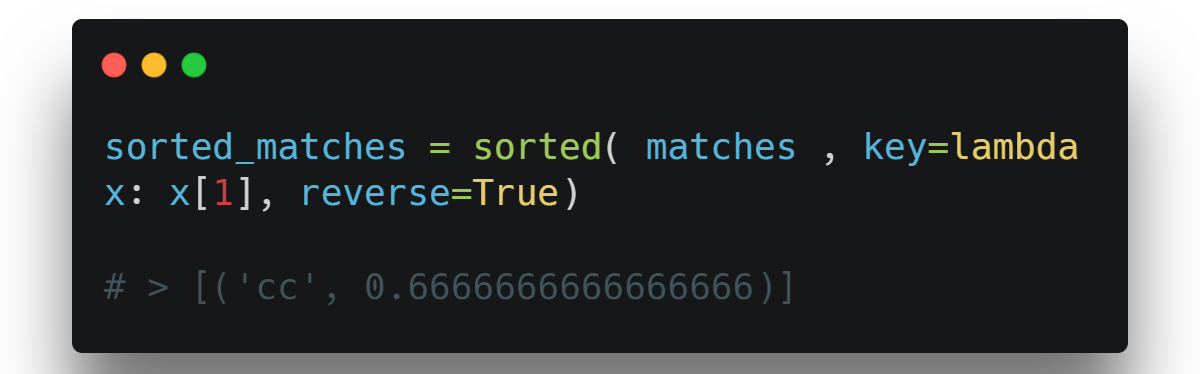
(3) Sort to find the best match:
Sort the filtered results, so the best result is in index position 0. This is an O(n) to O(n log n) operation (for Timsort: i.e. Insertion or Merge).
(4) Get the top match or Handle if there are no matches. Ensure a value is returned:
We’re using float('nan') here because it should never unintentionally match a genuine key. Python doesn’t have a true null type (i.e. None == None is True, which is not the case for null) . float('nan') provides that null behaviour. This is an O(1) operation.

(5) Extract the key value (i.e. from (key,score) tuple) or handle no matches:
Same reasoning applies for float('nan') to ensure the null result it will not match an existing dictionary key. This is an O(1) operation.

(6) Second-Level Get_or_Else Lookup:
A simple get_or_else lookup. Note, that if a top_match_key was not found, then its value will be float('nan'), which will not match. Therefore, it will fail and return the specified default_value. This is an O(1) operation.

Runtime Analysis
For the eager implementation, total time complexity is O(3n+3c) for average, worst and best case scenarios (excluding variations in dependent functions, e.g. Timsort). Comparatively, dict‘s native lookup is O(1).
Pros:
- Relatively simple code to write.
Cons:
- Bad for dictionaries with large key sets.
- Guaranteed O(3n+3c) for dictionary lookups.
Lazy Implementation:
For the lazy implementation, total time complexity is O(3n+3c) for average and worst case scenarios and best as O(1). Best case improvement is achieved by separating the boolean and confidence-based lookups into (curried, yet) separate function calls.
This implementation improves the best case execution time. In this case the similarity lookup is optional, and lazily called. If key is not found within the dictionary, get_or_threshold_match_lazy() will return a function (object) pointer, which can then be called. Note: the major difference in this function is on line 11.

Why? Well, the eager implementation (above) will first evaluate the O(3n+3c) lookup, then it will try the O(1) lookup. The lazy implementation, will first evaluate the O(1) lookup, then it will wait for evaluation of the O(3n+3c) lookup.
Pros:
- Time complexity best case is O(1). Still average and worst is O(3n+3c).
- An option to separate function calls, and conditionally request the secondary function.
- Good for large lookup dictionaries.
Cons:
- More complex code to write / read.
Related Techniques:
It is important to note that this problem is elsewhere too, and not simply a current issue in data cleaning. In the area of similarity string-matching there are a number of techniques to consider (e.g. Hamming distance, Levenshtein distance, Longest common subsequence, fuzzy-string searching, etc.). Any of these could be used instead of the difflib library’s implementation.
When the data is large and comparing M x N values is infeasible, a set of other techniques is available; as noted in the article these include Shingling (a set of subsequences; e.g. n-grams), Minhashing (for conditional set-based pairing), Minhashing with Jaccard Similarity (Jaccardian ratio of matching conditional set factors), Locality-sensitive hashing (LSH).
Techniques used in natural language processing and information retrieval include term frequency–inverse document frequency (TF-IDF), word vectors (word2vec, Mikolov, etal. NIPS 2013), the encoder-decoder architectures, and more recent positional encoding in transformer (wiki) architectures (Vaswani’s transformer, 2017).
Reflections
It’s fair to consider the Related Techniques instead of the proposal above to extend dict.get() with confidence-based lookup.
In the case of dictionary lookups in terms of cross-language data cleaning (such as I am doing regularly in Pandas dataframes), similarity string-matching is (for me) the simplest choice while achieving reasonably adequate results.

